深入Dapper.NET源碼
深入Dapper.NET源碼
目錄
1.前言、目錄、安裝環境
建立.NET Core Console專案

需要安裝NuGet SqlClient套件、添加Dapper Project Reference

下中斷點運行就可以Runtime查看邏輯

2.Dynamic Query 原理 Part1
實體類別其實是
DapperRow再隱性轉型為dynamic。


3.Dynamic Query 原理 Part2
接著查看源碼GetDapperRowDeserializer方法,它掌管dynamic如何運行的邏輯,並動態建立成Func給上層API呼叫、緩存重複利用。 
DapperTable雖然是方法內的局部變量,但是被生成的Func引用,所以
不會被GC一直保存在內存內重複利用。
DapperRowMetaObject主要功能是定義行為,藉由override
BindSetMember、BindGetMember方法,Dapper定義了Get、Set的行為分別使用IDictionary<string, object> - GetItem方法跟DapperRow - SetValue方法


4. Strongly Typed Mapping 原理 Part1 : ADO.NET對比Dapper
ADO.NET對比Dapper

需要手動解壓縮到
%USERPROFILE%\Documents\Visual Studio 2019路徑下面
.netstandard2.0專案,需要建立netstandard2.0並解壓縮到該資料夾
最後重開visaul studio並debug運行,進到GetTypeDeserializerImpl方法,對DynamicMethod點擊放大鏡 > IL visualizer > 查看Runtime生成的IL代碼 
5. Strongly Typed Mapping 原理 Part2 : Reflection版本
不應該重複屬性查詢,沒用到就要忽略 舉例 : 假如類別有N個屬性,SQL指查詢3個欄位,土炮ORM每次PropertyInfo foreach還是N次不是3次。而Dapper在Emit IL當中特別優化此段邏輯 :
「查多少用多少,不浪費」(這段之後講解)。

使用字串Key取值會多呼叫了
GetOrdinal方法,可以查看MSDN官方解釋,效率比Index取值差。

6.Strongly Typed Mapping 原理 Part3 : 動態建立方法重要概念「結果反推程式碼」優化效率
7.Strongly Typed Mapping 原理 Part4 : Expression版本
可讀性好,可用熟悉的關鍵字,像是變量Variable對應Expression.Variable、建立物件New對應Expression.New
方便Runtime Debug,可以在Debug模式下看到Expression對應邏輯代碼

查詢效果圖 : 

8. Strongly Typed Mapping 原理 Part5 : Emit IL反建立C#代碼

netstandard不支援此方式,Dapper需要使用
region if 指定版本來做區分,否則不能使用,如圖片

9.Strongly Typed Mapping 原理 Part6 : Emit版本

10.Dapper 效率快關鍵之一 : Cache 緩存原理
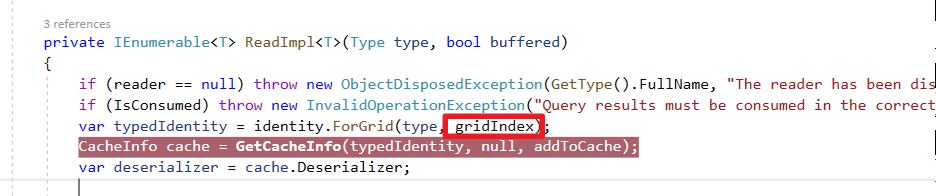
接著追蹤Dapper源碼,這次需要特別關注的是QueryImpl方法下的Identity、GetCacheInfo 
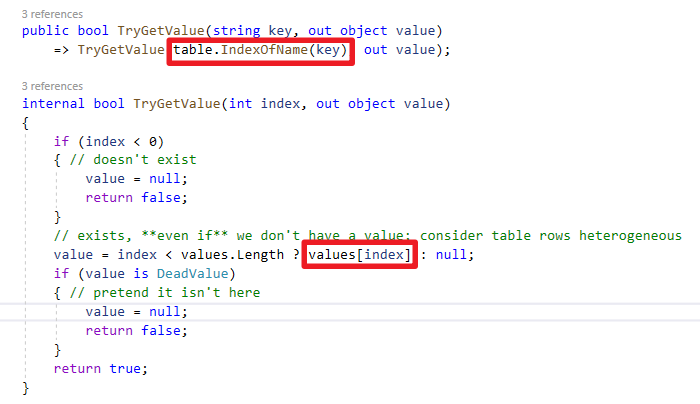
接著搭配GetCacheInfo方法內Dapper使用的緩存類別ConcurrentDictionary<Identity, CacheInfo>,使用TryGetValue方法時會去先比對HashCode接著比對Equals特性,如圖片源碼。 
效果圖 : 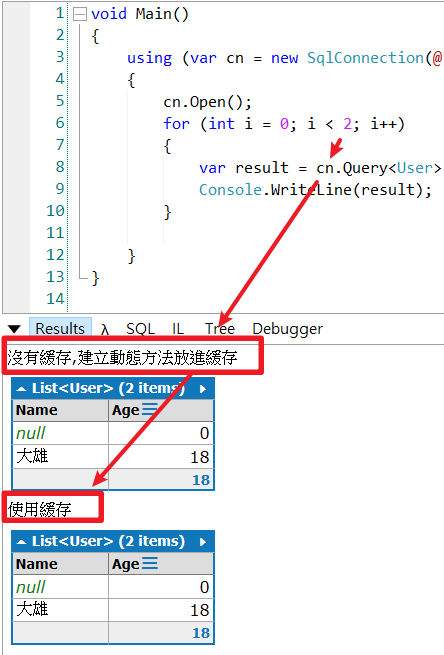
11.錯誤SQL字串拼接方式,會導致效率慢、內存洩漏



12.Dapper SQL正確字串拼接方式 : Literal Replacement
13.Query Multi Mapping 使用方式


SplitOn區分類別Mapping組別
Split預設是用來切割主鍵,所以預設切割字串是Id,假如當表格結構PK名稱為Id可以省略參數,舉例 
14.Query Multi Mapping 底層原理
Multiple Mapping 底層原理
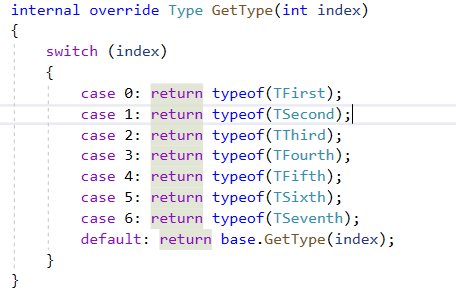
舉例,可以看到圖片GenerateMapper方法,依照泛型參數數量,寫死強轉型邏輯,這也是為何Multiple Query有最大組數限制,只能支持最多6組的原因。

這邊Dapper使用
泛型類別來強型別保存多類別的資料

首先
倒序方式處理欄位分組(GetNextSplit方法可以看到從DataReader Index大到小查詢)
最後反轉為
正序,方便後面Call Func對應泛型使用


15.QueryMultiple 底層原理




16.TypeHandler 自訂Mapping邏輯使用、底層邏輯
效果圖 : 
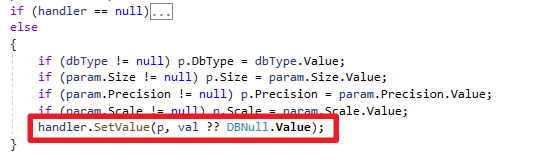
SetValue底層原理
在Runtime呼叫AddParameters方法時會使用LookupDbType,判斷是否有自訂TypeHandler


接著將建立好的Parameter傳給自訂TypeHandler.SetValue方法


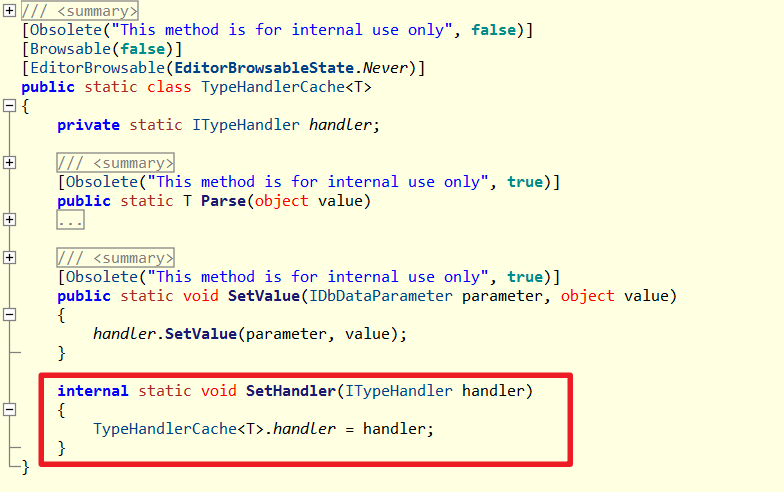
Parse對應底層原理
主要邏輯是在GenerateDeserializerFromMap方法Emit建立動態Mapping方法時,假如判斷TypeHandler緩存有資料,以Parse方法取代原本的Set屬性動作。 
17. CommandBehavior的細節處理
可按順序分次讀取資源,
避免二進制大資源一次性讀取到內存,尤其是Blob或是Clob會配合GetBytes 或 GetChars 方法限制緩衝區大小,微軟官方也特別標註注意 :
但它卻不是DataReader的預設行為,系統預設是CommandBehavior.Default  CommandBehavior.Default有著以下特性 :
CommandBehavior.Default有著以下特性 :

另外可以發現此段除了while (reader.NextResult()){}外還有while (reader.Read()) {},同樣是避免忽略錯誤,這是一些公司自行土炮ORM會忽略的地方。 
與QuerySingle之間的差別
這段有一個特別好玩小技巧可以學,錯誤處理直接沿用對應LINQ的Exception,舉例:超過一行資料錯誤,使用new int[2].Single(),這樣不用另外維護Exceptiono類別,還可以擁有i18N多國語言化。 

18.Parameter 參數化底層原理
19. IN 多集合參數化底層原理
關鍵程式部分 
 SQL參數字串的取代邏輯也寫在這邊,如圖片
SQL參數字串的取代邏輯也寫在這邊,如圖片 
20.DynamicParameter 底層原理、自訂實作
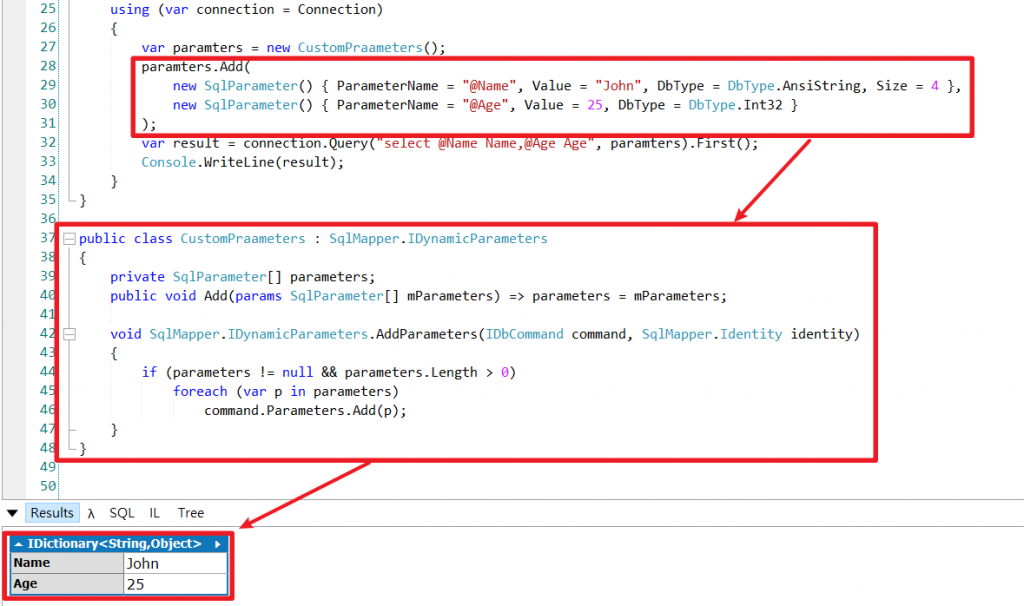
21. 單次、多次 Execute 底層原理
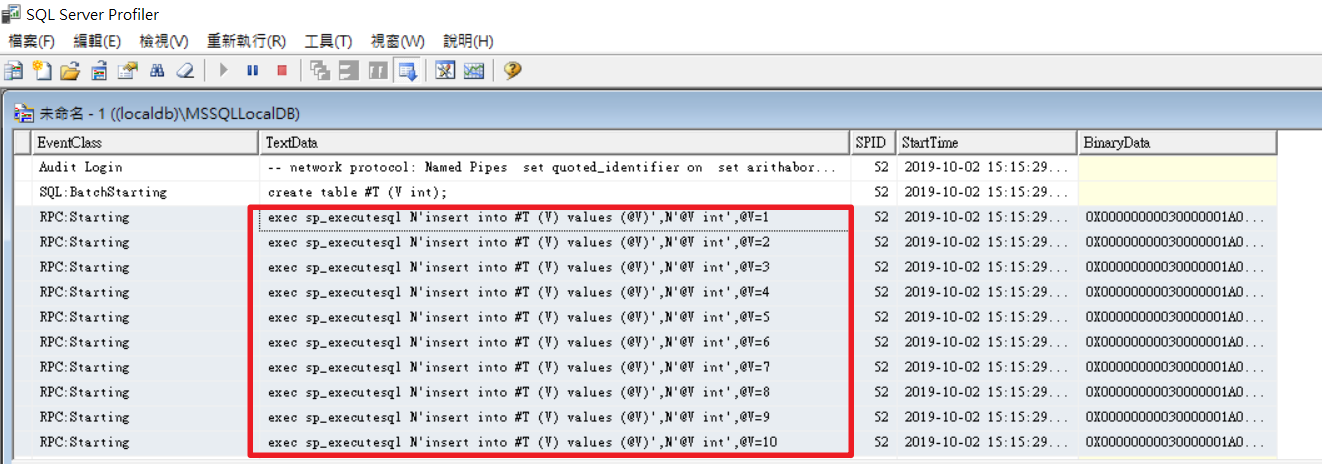
以單次執行來說Dapper Execute底層是ADO.NET的ExecuteNonQuery的封裝,封裝目的為了跟Dapper的Parameter、緩存功能搭配使用,代碼邏輯簡潔明瞭這邊就不做多說明,如圖片 
確認是否為集合參數

建立
一個共同DbCommand提供foreach迭代使用,避免重複建立浪費資源
假如是集合參數,建立Emit IL動態方法,並放在緩存內利用

22. ExecuteScalar應用
首先,Entity Framwork如何高效率判斷資料是否存在?
效果圖 : 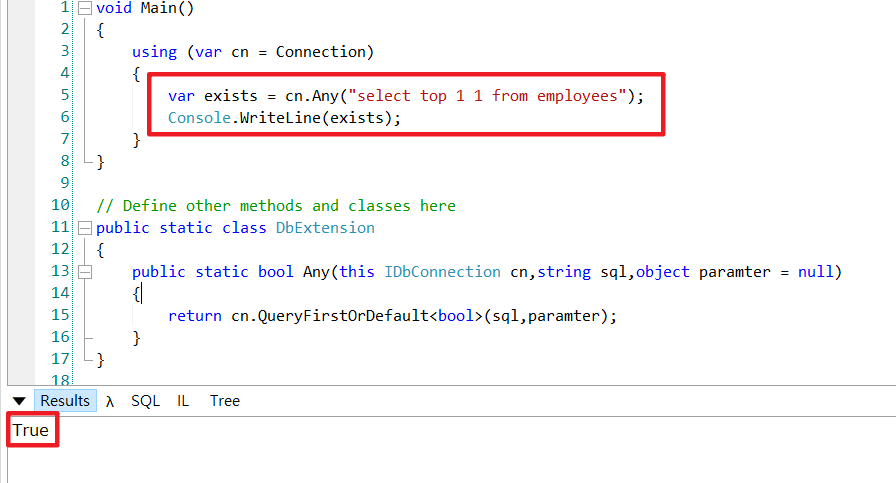
不要QueryFirstOrDefault代替,因為它需要在SQL額外做Null的判斷,否則會出現「NullReferenceException」。 
這原因是兩者Parse實作方式不一樣,QueryFirstOrDefault判斷結果為null時直接強轉型 
而ExecuteScalar的Parce實作多了為空時使用default值的判斷 
23.總結
連結 : c# - How to remove the last few segments of Emit IL at runtime - Stack Overflow 
Last updated